Who picks the model?
Not the developer.

The first thing a developer building an AI app does is pick a model. A few weeks after launch, they pick a router.
But it wasn’t always like this. A year ago, most startups picked one model and built everything around it. Today they’re using a handful, picking different models to cut token spend and get better results on specific tasks. Ever noticed how AI apps often hide the model name and just say “Default”? That’s routing.
Most people think we’re headed for a world with one or two dominant model providers, where frontier labs keep getting stronger and developer lock-in keeps deepening. If that’s right, routing doesn’t really matter and this post is pointless. In that future, there’s nothing to route between. You just pick a model and it does everything.
But that’s not what’s happening. Things feel like they’re moving in the other direction. Cursor built its own coding model, Harvey fine-tunes for legal, and Suno built its own model for music. Maybe most importantly, the number of open source models with real adoption is exploding. It’s becoming hard to ignore that specialized models win on specific jobs.
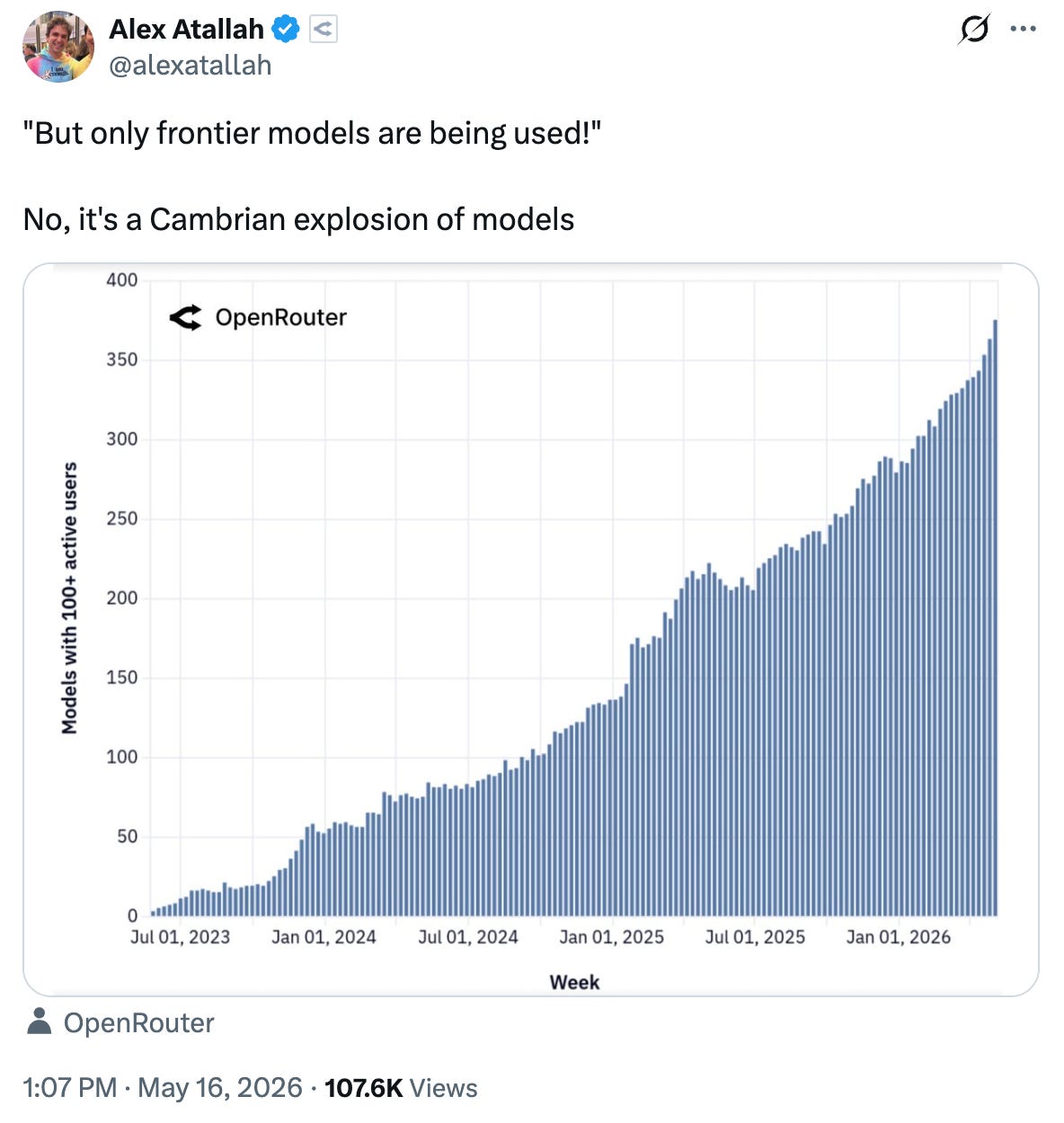
Is routing the AI era’s load balancer? Probably. The developer picks the router, and the router picks the model, manages cost and latency, and reroutes when models go down. Whoever owns the router sits underneath everything else. The margins for a router business are still an open question, but the importance of the layer itself is not.
The real question is whether routing stays a feature that platforms bolt on, or becomes its own thing with real network effects. That’s the kind of question we’re always asking at USV.
It comes down to whether routing gets better the more traffic it sees, and right now it looks like it does. A router that sees traffic from thousands of apps knows which models actually work for which jobs. A single app never will.
thank you, we wrote about models recently too. this is the a very clean writeup of the routing thesis